




















 问一问
问一问一、了解一下因子
因子投资是时下投资界非常热门的方向。甚至有人戏称因子研究是“诺贝尔奖收制机”:1990年,哈里·马科维茨凭借“均值一方差分析”获得了诺贝尔经济学奖:同年,威廉·夏普凭借他的“资本资产定价模型”也摘得诺贝尔奖桂冠:到了2013年,提出Fama-French三因子模型的尤金·法马也获得了诺贝尔经济学奖,同时,Fama-french三因子模型也被认定为金融领域的重大成就之一。
那么,到底什么是“因子”呢?
其实因子就是影响股票涨跌的原因,例如主力资金。因子模型就是去寻找因子与股价之间的关联。
获取量化软件,低费率账户,添加经理联系方式哦!!!
二、获取主力资金流向数据
相信朋友们已经会使用getmoney_fow函数获取了股票的资金流入/流出数据并且发现了一个可能存在的规律--某日该股票价格上涨,且主力资金净流入的话,次日股价可能上涨;否则股价下跌。为了进行实验,这里再次获取股票的资金流入/流出数据为了便于后面训练模型,这次我们把数据的时间范围扩大至2年。输入代码如下:
from jqdata import *# 使用 get_money_flow 函数获取数据df = get_money_flow('002458.XSHE',fields=['date', 'sec_code', 'change_pct', 'net_amount_main', 'net_pct_main'],start_date='2023-06-04',end_date='2025-06-04')# 检查是否成功print(df.head())
运行代码结果: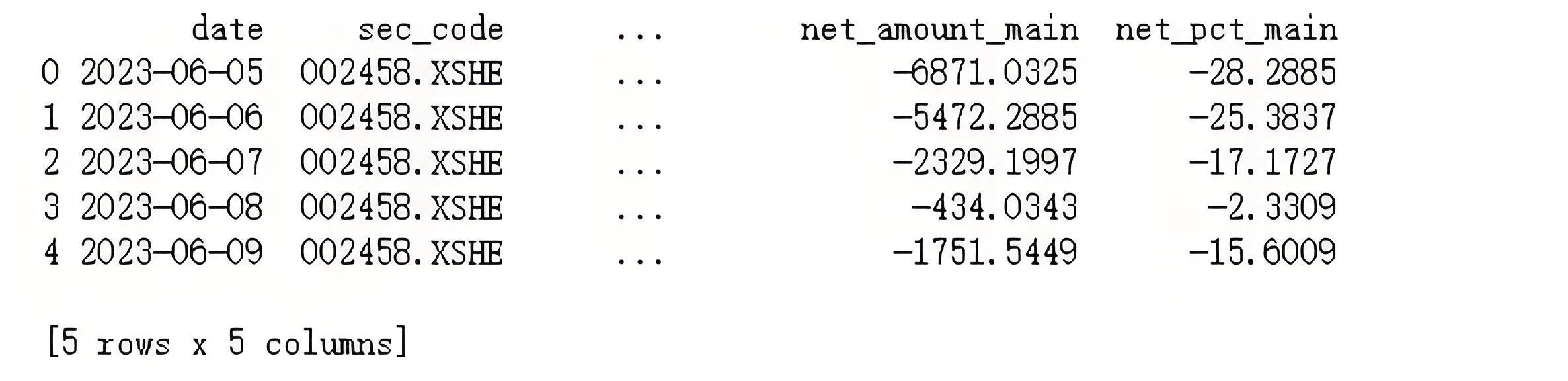
三、简易的特征工程
下面我们给原始的数据增加两个新的字段,其中一个是upor_down,用来表示当日股价是上涨还是下跌。如果change_pct(涨幅)这个字段为正数,说明股价上涨,则up_or_down用1来表示,反之,用0表示,代表当日股价下跌。
类似地,我们用 money_in_out 字段表示主力资金净流入还是净流出。如果net_amountmain 大于 0,说明主力资金净流入,则在money_in_out字段用1表示;反之说明主力资金净流出,money_in_out字段用0表示。示例代码如下:
# 增加一个字段,记录股价上涨还是下跌# 如果股价上涨,则以 1 标记,否则以 0 标记df['up_or_down'] = np.where(df['change_pct'] > 0, 1, 0)# 增加一个字段,记录主力资金净流入还是流出# 如果净流入,标记为 1,否则标记为 0df['money_in_out'] = np.where(df['net_amount_main'] > 0, 1, 0)# 检查是否成功print(df.head())
运行代码

可以看到,2023年6月8日主力资金全是净流出,所以标记为0,但是涨了,标记为1、
这样说明我们的特征工程成功了。
四、资金量因子了解一下
现在我们有了两个新的特征,能够体现股价的涨跌和主力资金的流入/流出情况,下面就可以用这两个新的特征来计算“资金量因子”了,为了方便大家理解,我给他取名1号因子。
咱们先说说思路。如果我们把两个特征相乘,则当股价上涨,且主力资金净流入时,因子值就是up_or_down乘以money_in_out,也就是1×1,结果是1;而其他情况,“1号因子”的数值都为0。例如,股价下跌但主力资金净流入,“1号因子”为0×1,结果为0。同时,为了后面便于模型训练,我们还要做一个标签(即次日股票上涨还是下跌),存储在next_day字段中。代码如下:
# 两个自增的字段相乘,得出因子值df['factor_xi'] = df['up_or_down'] * df['money_in_out']# 把次日涨跌作为预测标签存储到 next_day 字段df['next_day'] = df['up_or_down'].shift(-1)# 检查是否成功print(df.head())
运行代码:
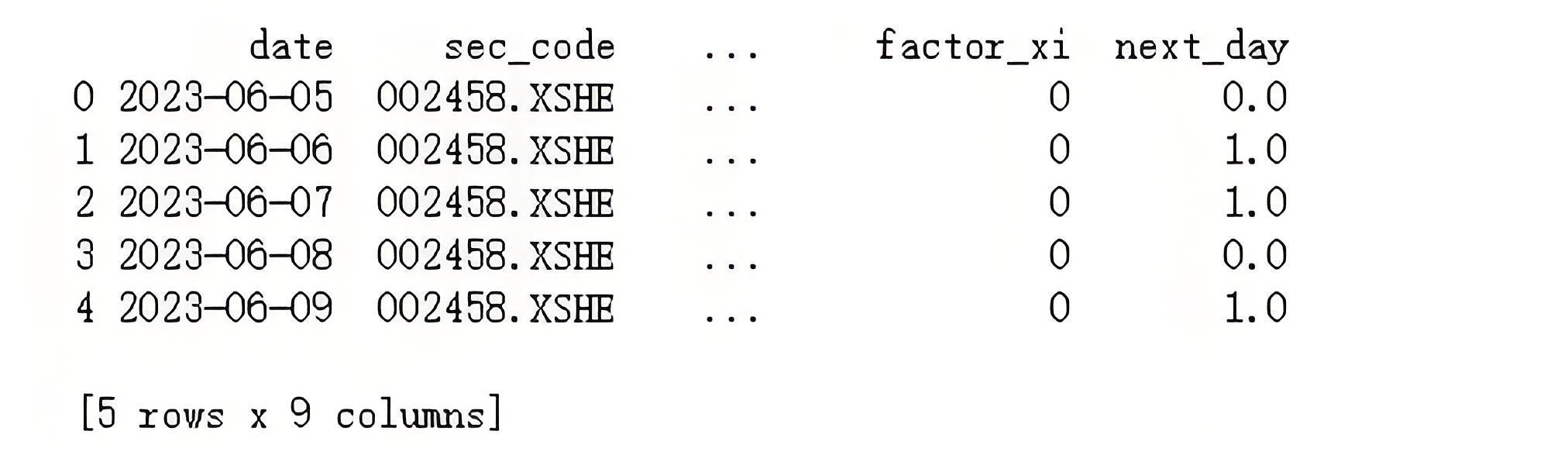
从表中我们可以看到,1号因子已经添加成功了,全是0蛋。
五、用添加“1号因子”的数据训练模型
既然我们已经有了1号因子,不如加入模型看看准确率是否提高。
下面我们导入机器学习工具,并且准备训练模型用的数据集。
代码:
from sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_split# 在数据集中,把日期、股票代码及我们添加的特征去掉# 注意:字段名需要与 df 中的字段名一致dataset = df.drop(['date', 'sec_code', 'up_or_down', 'money_in_out'], axis=1)# 检查是否成功print(dataset.head())
结果展示:
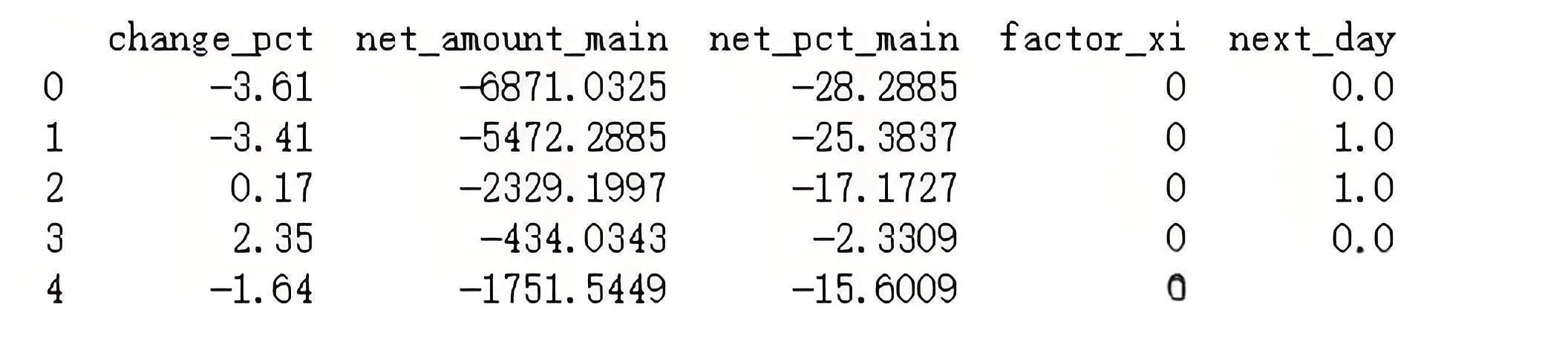
因为最后一天是没有next day数据的(因为对于最后一天来说,下一个交易日还没到来),所以我们要去掉最后一行数据:同时,把除标签以外的特征赋值给X,把标签赋值给y;再使用数据集拆分工具,将X和y分别拆分成训练集和验证集。输入代码如下:
# 将 'next_day' 作为数据集的标签y = dataset['next_day'][:-1].fillna(0) # 处理 NaN 值# 去掉 'next_day' 字段,并去掉最后一行(因为最后一行的 'next_day' 是 NaN)X = dataset.drop(['next_day'], axis=1)[:-1]# 将数据集拆分为训练集和验证集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=28)# 检查数据集是否正确拆分print("训练集特征形状:", X_train.shape)print("测试集特征形状:", X_test.shape)print("训练集标签形状:", y_train.shape)print("测试集标签形状:", y_test.shape)
下面就可以训练模型,使用的还是朋友们已经比较熟悉的KNN分类算法。输入代码如下:
# 创建 KNN 分类器,n_neighbors 参数取 72knn = KNeighborsClassifier(n_neighbors=72)# 使用训练集训练模型knn.fit(X_train, y_train)# 输出训练集中的模型准确率print("训练集准确率:", knn.score(X_train, y_train))# 输出验证集中的模型准确率print("验证集准确率:", knn.score(X_test, y_test))
输出结果:

到此为止,我们成功地失败了,验证集的准确率只有52.89%
大家可以去试试其他的票和间隔。
今天的完整代码,考虑到很多朋友没有QMT和PT,今天用的是聚宽,复制到聚宽就可以实现,聚宽虽然不能交易,但是用来研究还是可以的。
import numpy as npimport pandas as pdfrom jqdata import *from sklearn.neighbors import KNeighborsClassifierfrom sklearn.model_selection import train_test_split# 使用 get_money_flow 函数获取数据df = get_money_flow('002458.XSHE',fields=['date', 'sec_code', 'change_pct', 'net_amount_main', 'net_pct_main'],start_date='2023-06-04',end_date='2025-06-04')# 增加一个字段,记录股价上涨还是下跌# 如果股价上涨,则以 1 标记,否则以 0 标记df['up_or_down'] = np.where(df['change_pct'] > 0, 1, 0)# 增加一个字段,记录主力资金净流入还是流出# 如果净流入,标记为 1,否则标记为 0df['money_in_out'] = np.where(df['net_amount_main'] > 0, 1, 0)# 两个自增的字段相乘,得出因子值df['factor_xi'] = df['up_or_down'] * df['money_in_out']# 把次日涨跌作为预测标签存储到 next_day 字段df['next_day'] = df['up_or_down'].shift(-1)# 在数据集中,把日期、股票代码及我们添加的特征去掉# 注意:字段名需要与 df 中的字段名一致dataset = df.drop(['date', 'sec_code', 'up_or_down', 'money_in_out'], axis=1)# 检查是否成功print(dataset.head())# 将 'next_day' 作为数据集的标签y = dataset['next_day'][:-1].fillna(0) # 处理 NaN 值# 去掉 'next_day' 字段,并去掉最后一行(因为最后一行的 'next_day' 是 NaN)X = dataset.drop(['next_day'], axis=1)[:-1]# 将数据集拆分为训练集和验证集X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=28)# 检查数据集是否正确拆分print("训练集特征形状:", X_train.shape)print("测试集特征形状:", X_test.shape)print("训练集标签形状:", y_train.shape)print("测试集标签形状:", y_test.shape)# 创建 KNN 分类器,n_neighbors 参数取 72knn = KNeighborsClassifier(n_neighbors=72)# 使用训练集训练模型knn.fit(X_train, y_train)# 输出训练集中的模型准确率print("训练集准确率:", knn.score(X_train, y_train))# 输出验证集中的模型准确率print("验证集准确率:", knn.score(X_test, y_test))

 当前我在线
当前我在线
 直接咨询我
直接咨询我
文章很精彩?转发给需要的朋友吧 
 分享该文章
分享该文章


 586
586




















 +微信
+微信
 电话
电话

 公网安备:11010802032515号 ICP备案:京ICP备18019099号-3
公网安备:11010802032515号 ICP备案:京ICP备18019099号-3